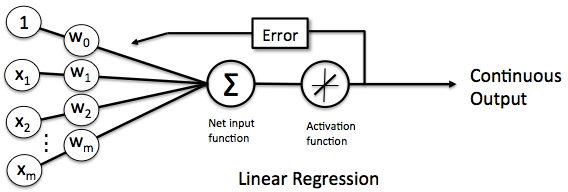
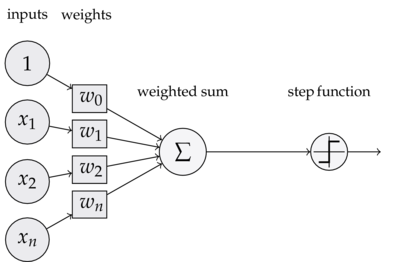
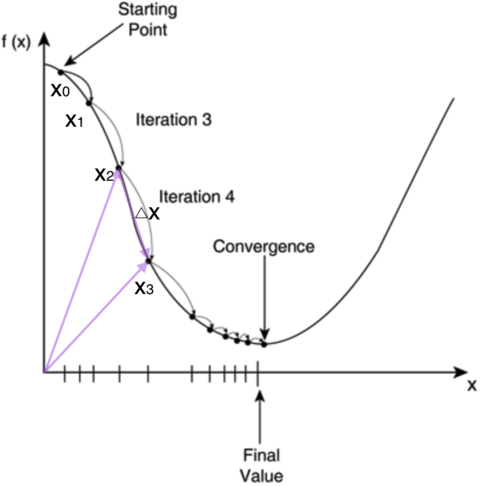
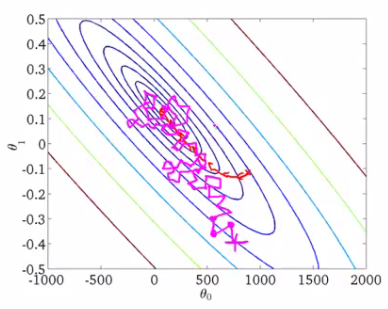
TensorFlow 简介
TensorFlow™ 是一个使用数据流图进行数值计算的开源软件库。图中的节点代表数学运算, 而图中的边则代表在这些节点之间传递的多维数组(张量)。这种灵活的架构可让您使用一个 API 将计算工作部署到桌面设备、服务器或者移动设备中的一个或多个 CPU 或 GPU。 TensorFlow 最初是由 Google 机器智能研究部门的 Google Brain 团队中的研究人员和工程师开发的,用于进行机器学习和深度神经网络研究, 但它是一个非常基础的系统,因此也可以应用于众多其他领域。
TensorFlow是开源数学计算引擎,由Google创造,用Apache 2.0协议发布。TF的API是Python的,但底层是C++。和Theano不同,TF兼顾了工业和研究,在RankBrain、DeepDream等项目中使用。TF可以在单个CPU或GPU,移动设备以及大规模分布式系统中使用。