转载自-李虹磊 基于迁移学习和深度神经网络的序列标注方法
论文题目:Transfer learning for sequence tagging with hierarchical recurrent networks
论文作者:Zhilin Yang, Ruslan Salakhutdinov, William W. Cohen
School of Computer Science Carnegie Mellon University
论文出处:Published as a conference paper at ICLR 2017
摘要
本文利用迁移学习的思想和神经网络模型来解决序列标注问题。使用有大量已标注数据集的任务作为源数据领域,来提升只有少量标注数据的目标任务的性能。本文从跨域、跨应用和跨语言三个迁移设置来验证迁移学习用于深度层级循环神经网络中的性能。实验表明,在深度层级神经网络的基础上使用迁移学习的思想可以显著提高序列标注的性能。
一、序列标注问题
序列标注是自然语言处理的一个重要研究课题,有着广泛的应用,包括词性标注、文本语块分析和命名实体识别等。给定单词序列,序列标注问题旨在为每个单词预测对应的标签,例如词性、实体名称等。
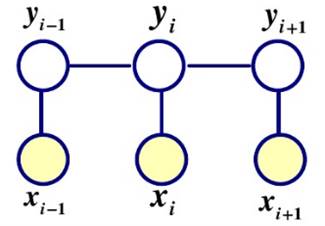
针对序列标注问题,比较常用的方法有条件随机场(CRF)。条件随机场是一种判别式模型,是指在给定输入条件下,计算输出的条件概率,其核心思想是利用无向图理论使序列标注的结果达到在整个序列上全局最优。当用于序列标记任务时,一般假设图是最简单和最通用的图结构,将其称为线性链条件随机场( Linear-chain CRF ),结构如下图所示。
随着深度学习的广泛应用,深度神经网络,如RNN、LSTM、BILSTM、GRU等模型也应用于序列标注问题中。
LSTM:像RNN、LSTM、BILSTM这些模型,它们在序列建模上很强大,它们能够capture长远的上下文信息,此外还具备神经网络拟合非线性的能力,这些都是crf无法超越的地方。但如果标签之间存在较强的依赖关系的话(例如,形容词后面一般接名词,存在一定的约束),LSTM无法对这些约束进行建模,LSTM模型的性能将受到限制。
CRF:它不像LSTM等模型,能够考虑长远的上下文信息,它更多考虑的是整个句子的局部特征的线性加权组合(通过特征模版扫描整个句子)。关键的一点是,CRF的模型为$p(y | x, w)$,注意这里y和x都是序列,所以目标是优化一个序列$y = ( y_1, y_2, …, y_n)$,而不是某个时刻的$y_t$,即找到一个概率最高的序列$y = (y_1, y_2, …, y_n)$使得$p ( y_1, y_2, …, y_n | x, w)$最高,它计算的是一种联合概率,优化的是整个序列(最终目标),而不是将每个时刻的最优拼接起来,在这一点上CRF要优于LSTM。
CNN+BILSTM+CRF:这是目前学术界比较流行的做法,BILSTM+CRF是为了结合以上两个模型的优点,CNN主要是处理英文的情况,英文单词是由更细粒度的字母组成,这些字母潜藏着一些特征(例如:前缀后缀特征),通过CNN的卷积操作提取这些特征,在中文中可能并不适用。
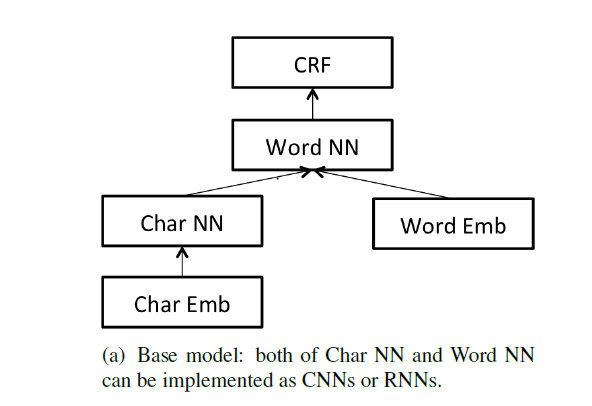
图2所示的用于序列标注问题的NN+CRF模型,是目前较为流行的层级框架。Character-level层将单词的字符表示为向量,作为NN的输入,经过神经网络的学习得到字符级别的关于形态信息的单词特征表示;在word-level层上将词向量和字符级别的特征表示进行拼接,输入到神经网络中进一步学习,输出新的特征表示,最后使用CRF层考虑前后标签的全局信息,优化整个序列的标签结果。
经过上述的分析,我们可以发现序列标注问题有着广泛的应用,包括词性标注、语块分析和命名实体识别等任务。那么,如何将一个任务的知识迁移到另一个任务呢?
再者,神经网络模型,有着显著的泛化特点,在没有改变结构的情况下可以应用到很多不同语言不同应用的任务中。那么是否有一种方法可以利用神经网络的泛化性,来通过与其他任务共享模型参数和特征表示来改善任务性能?
二、迁移学习
1、定义
传统机器学习中,通常会针对每个任务从头开始搭建模型,这样做是非常耗时和昂贵的,而且有些目标任务只有少量的标记数据。但其实不同任务之间可能有一些相似性,一些已有的知识是能够帮助于当前任务的。迁移学习的思想,就是运用已有的知识来学习新的知识,找到已有知识和新知识之间的相似性,有点类似于举一反三。对于已有的知识我们叫做源域(source domain),要学习的新知识叫做目标域(target domain)。迁移学习就是研究如何把源域的知识迁移到目标域上。
在教育和心理学上,迁移学习的定义是基于人类已有的经验来研究人类的行为、学习或表现。探讨人类如何从一个环境中迁移到具有相似特性的另一个环境中。任何一种学习都要受到学习者已有知识经验、技能、态度等的影响,只要有学习,就有迁移。
在机器学习中,维基百科给出的解释翻译过来就是,归纳迁移,也叫做迁移学习,是机器学习中的一个研究问题。它侧重于把解决某一问题时的知识储存起来,以便应用到不同、但是相关的其他问题上去。例如,已经会编写了C++,就可以类别着学习Java;已经学会了英语,可以类比着学习法语,等等。所以,找到不同任务之间的相似性,利用这个相似性就可以辅助学习新的知识。
2、趋势
吴恩达说在他的 NIPS 2016 tutorial 中曾说,迁移学习将成为机器学习工业应用中取得成功的关键推动力。迁移学习将是监督学习之后的,在ML的商业应用中得到成功的下一波动力。
迁移学习可以帮助我们处理新遇到的场景,并且迁移学习是机器学习的工业规模使用所必须的,它超越了任务的限制,而且域有丰富的标记数据。到目前为止,我们已经将模型有效应用于在数据可用性方面非常易得的任务和域,必须学会将所获得的知识迁移到新的任务和域。
深度学习和迁移学习的结合:深度学习网络可以学习到数据的非线性表示,是多层级的,大数据背景下会有很好的性能;而迁移学习可以缓解对少量数据学习能力不足的问题,用已有的知识来学习未知的知识。
##三、本文方法
###1、主要工作
提出了一种基于深层级循环神经网络和迁移学习的序列标注方法,该方法在源任务和目标任务之间共享隐藏特征表示和模型参数的一部分;并结合两项任务的目标函数,采用基于梯度的方法进行有效的训练;研究跨域,跨应用和跨语言迁移学习,并为每种情况提出一个参数共享框架图。
###2、分类
自然语言处理(NLP)任务中的转移学习有两种常见的范例,基于资源的转移和基于模型的转移。基于资源的转移利用额外的语言标注数据作为迁移学习的弱监督,如跨语言字典、语料库和字对齐。基于资源的方法在跨语言迁移方面取得了相当大的成功,但对附加资源的规模和质量相当敏感。在以前的研究中,基于资源的转移主要限于跨语言迁移,将基于资源的迁移方法扩展到跨域和跨应用迁移中,目前还没有广泛的研究。
基于模型的迁移学习利用源任务和目标任务之间的相似性和相关性,通过自适应地修改模型架构,训练算法或特征表示。
本文方法采用基于模型的迁移学习,并结合深度循环神经网络,实现跨域、跨应用、跨语言的知识迁移,以提升序列标注性能。
按照我的理解,域就是指做在不同数据域做同一种任务,例如博客中的命名实体识别和生物医学文本中的命名实体识别;应用就是指不同任务,例如命名实体任务和词性标注;语言就很好理解,例如英语和西班牙语。
3、方法
以下是本文提出的三种迁移学习框架:
这三种框架都是基于图2中的NN+CRF模型,并共享模型的不同参数设置所提出的。
1)Transfer Model T-A:用于源域和目标域的标签之间可以映射的跨域迁移学习。
因为标签之间可以映射,所以可以共享整个模型的参数,一同训练。在CRF层输出之后,再完成目标任务的标签映射即可。
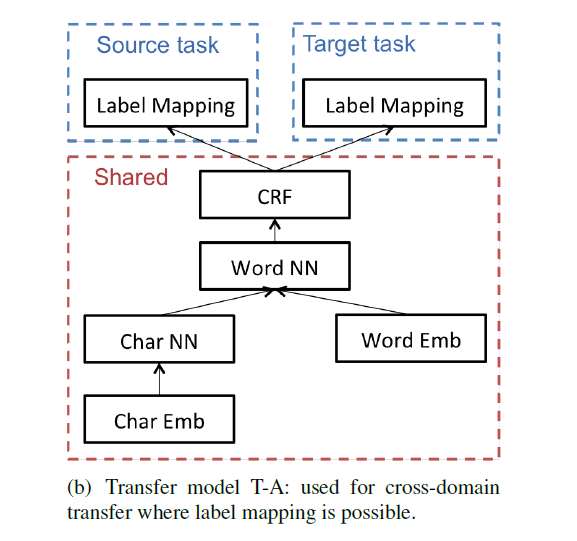
2)Transfer model T-B: 用于源域和目标域的标签之间不可以映射的跨域迁移学习,以及用于跨应用迁移学习。
标签之间不能映射,所以设计独立的CRF层,对源任务和目标任务分别进行序列标记。
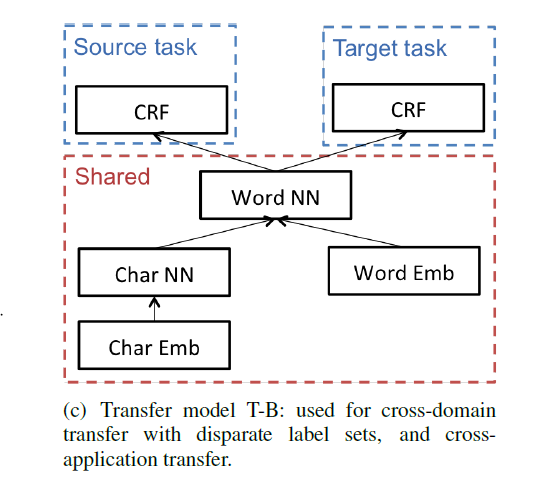
3)Transfer model T-C: 用于跨语言迁移学习。
鉴于跨语言迁移的难度,本文的跨语言迁移学习限制在有着相似字母表的语言之间,例如英语和西班牙语。因为有着相似的形态,所以在character-level层设置参数共享,实现字符级别的特征向量表示。
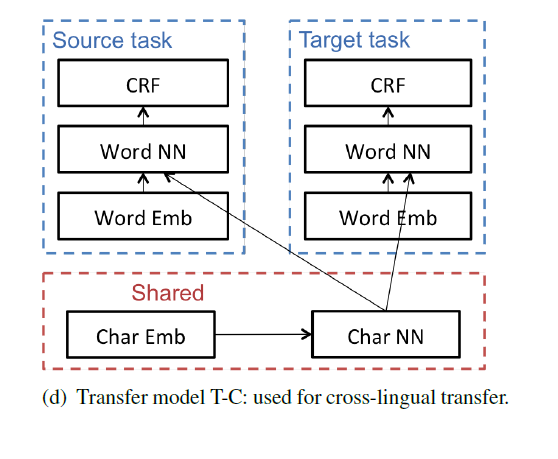
三个图中,红色框就是模型中参数共享的部分。
###4、模型训练
因为涉及两个域,即源数据域和目标数据域,所以分别表示source task和target task的参数,如下公式:
$$
W_s=W_{s,spc} \bigcup W_{shared}\\W_t = W_{t,spec}\bigcup W_{shared}
$$
其中,$W_{shared}$表示两个域的共享参数,$W_{s,spec}$表示源任务的参数,$W_{t,spec}$表示目标任务的参数。
训练要点如下:
1)每次迭代中,基于二项分布(二项概率设置为超参数)从任务{s,t}中采样一个任务;
2)对于采样到的任务,从任务中抽取一批实例,根据损失函数执行梯度更新;
3)训练过程中会更新所有参数,包括共享参数和两个任务特有参数;
4)采用AdaGrad动态计算每次迭代的学习率;
5)由于源任务和目标任务可能具有不同的收敛速度,所以在目标任务中使用early stopping。
5、实验效果
本文涉及的实验语料有Penn Treebank (PTB) POS tagging, CoNLL 2000 chunking, CoNLL 2003 English NER, CoNLL 2002 Dutch NER, CoNLL 2002 Spanish NER, the Genia biomedical corpus, and a Twitter corpus.
实验结果表明,在已标注数据不足的情况下,使用迁移学习可以显著提升序列标注性能;与其他方法相比,在已标注数据充裕的情况下,实验结果也是可比较的。另外,本文作者还观察到以下几点因素对于迁移学习的性能至关重要:目标任务中标签的丰裕度;源任务和目标任务的相关性;以及可以共享的参数的数量。
Reference:
[1] Pan S J, Yang Q. A survey on transfer learning[J]. IEEE Transactions on knowledge and data engineering, 2010, 22(10): 1345-1359.
[2] Jindong Wang. An Introduction to Transfer. Jun. 3, 2016.
[3] Qiang Yang. Transfer learning report. 2016.
[4] Lv X, Guan Y, Deng B. Transfer learning based clinical concept extraction on data from multiple sources[J]. Journal of biomedical informatics, 2014, 52: 55-64.
[5] Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.