介绍
论文提出了一个深度层叠循环神经网络的序列标注模型,这个模型是任务独立的,语言独立的,以及没有特征工程。论文探索了两种类型的联合训练,在多任务联合训练中,同种语言多个任务连个训练——英文的词性标注和实体识别。在跨语言联合训练中,模型训练同一个任务在不同的语言上——英文和西班牙语中的实体识别。论文表明多任务和跨语言的联合训练可以在不同场景提高性能。
模型
使用的是双向的GRU-CRF,网络的层数都是一层。
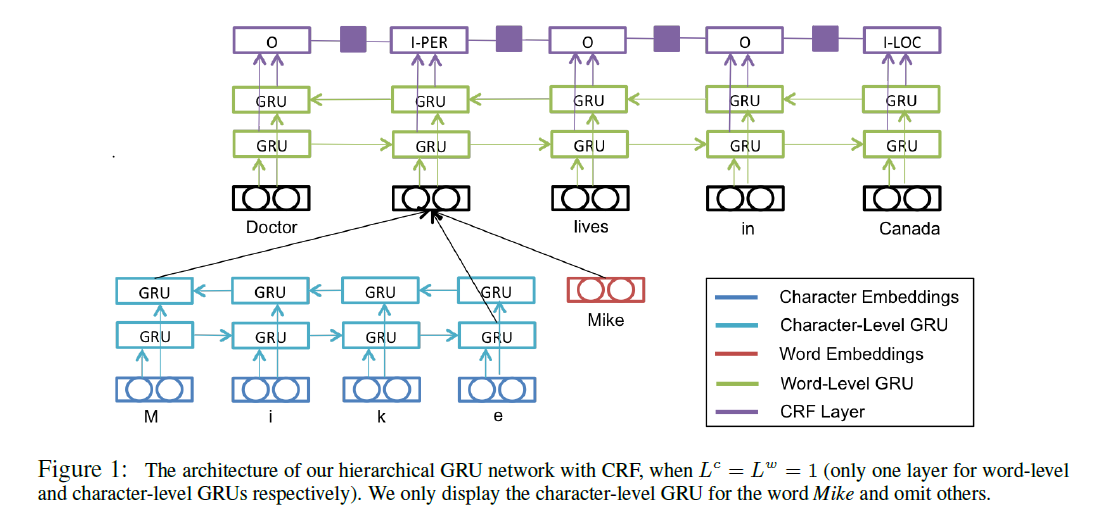
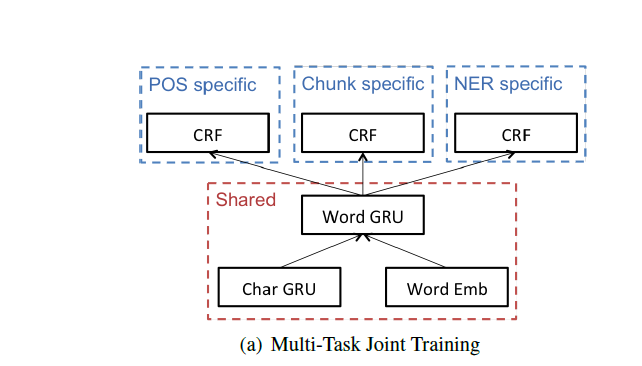
###多任务联合训练
共享字符级和词级参数,学习语言特有的规则。
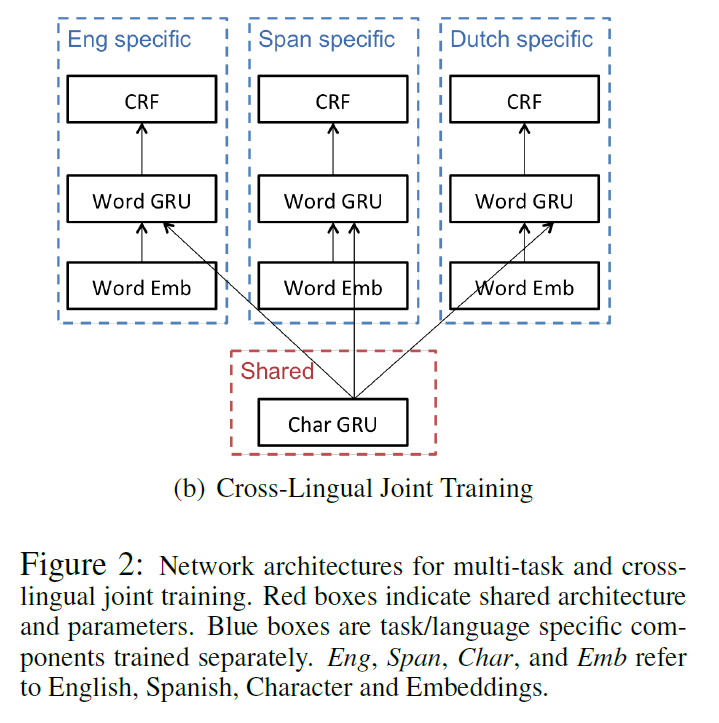
###跨语言联合训练
共享字符级的参数,在不使用平行语料或者词对齐的情况下,捕获语言之间的形态学相似性。
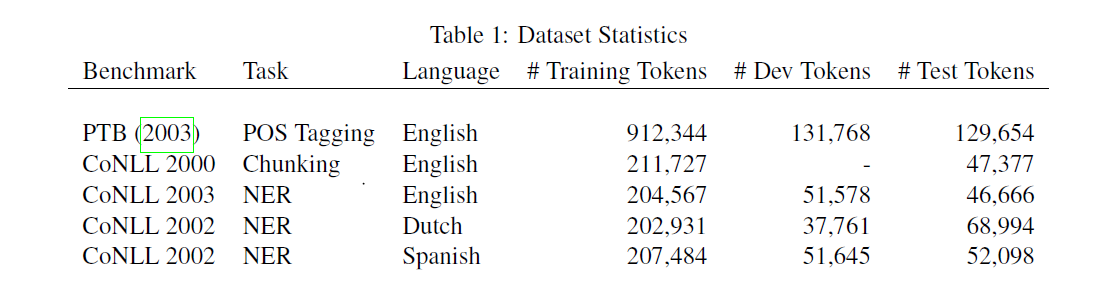
实验
数据集统计
实验结果
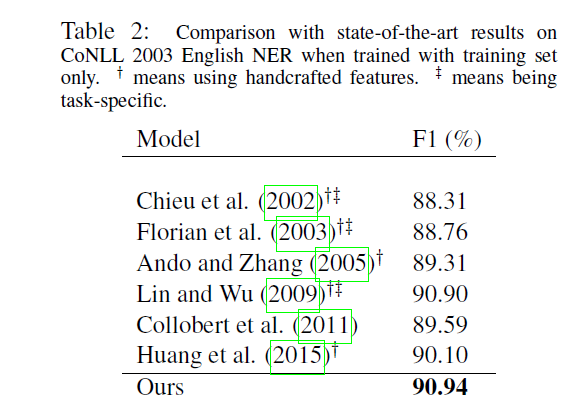
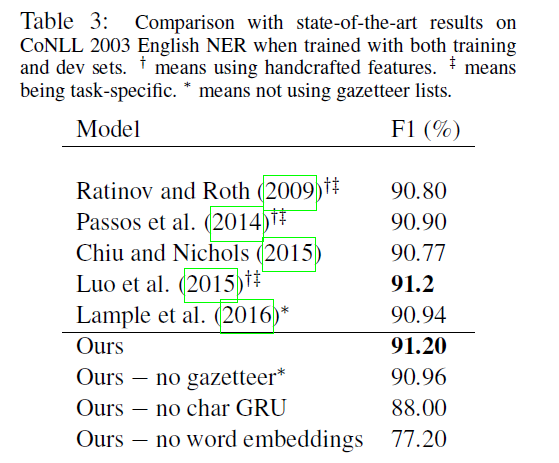
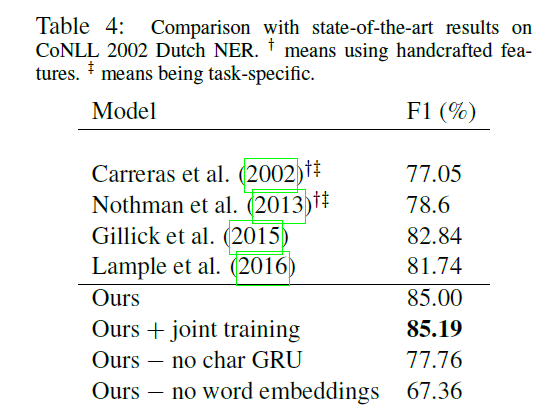
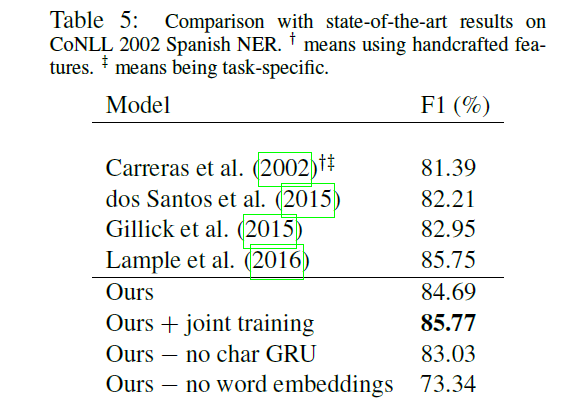
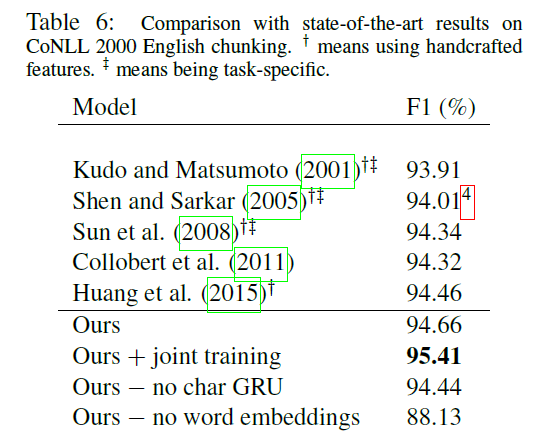
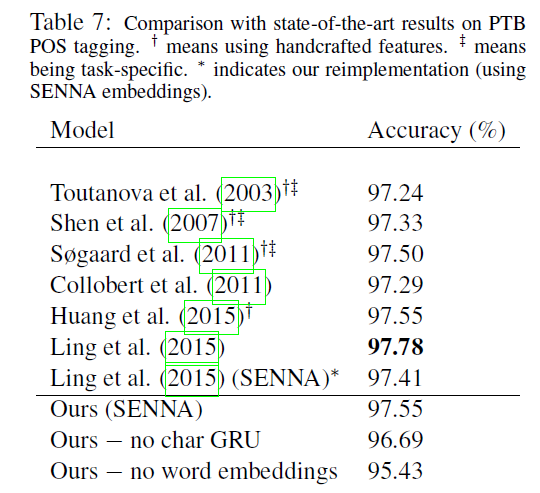
使用t-SNE对数据降维可视化
使用t-SNE在英语和西班牙语的字符级GRU输出降为2维的可视化,可以清楚的看到模型通过联合训练可以捕获两种语言的形态学相似性。

参考:Yang, Zhilin, Ruslan Salakhutdinov, and William Cohen. “Multi-task cross-lingual sequence tagging from scratch.” arXiv preprint arXiv:1603.06270 (2016).