介绍
使用递归神经网络进行语言建模的最新进展表明基于字符的语言建模是可行的。这篇论文提出利用一个预训练的字符语言模型的内部状态,以产生一种新型的字嵌入,称之为上下文字符串向量。我们提出的embedding有明显的优点:(1)在没有任何明确的词汇概念的情况下进行训练,从根本上将单词作为字符序列建模。(2)由其周围语境上下文化,这意味着相同的单词的embedding将根据其不同的语境的不同而不同。我们对先前的embedding进行比较评估,发现我们的embedding对于下游任务非常有用。在四个经典序列标记任务中,我们始终优于当前最优的结果。
在一个大规模未标注语料上进行训练,用来辅助学习和泛化放的的word embedding是一个关键的部分。目前最优的方法中连接了三种embedding:
- word embedding(Pennington et al., 2014; Mikolov et al., 2013):在大规模语料上预训练的,为捕捉潜在句法和语义相似性。
- Character-level features(Ma and Hovy, 2016; Lample et al., 2016):不是预训练,在任务数据上训练,为捕捉特点任务的词根特征(subword features)。
- Contextualized word embeddings(Peters et al., 2017; Peters et al., 2018):捕捉词在上下文中的语义,解决词汇的多义性和语境依赖性。
模型
在一个大规模无标注语料上预训练
捕获词在上下文的意思,因此可以对多义词根据他们的用法产生不同的embedding
对词和上下文作为一个字符的序列,可以更好的处理生僻词以及拼写错误的的单词和对词根(如前缀和后缀)的建模。
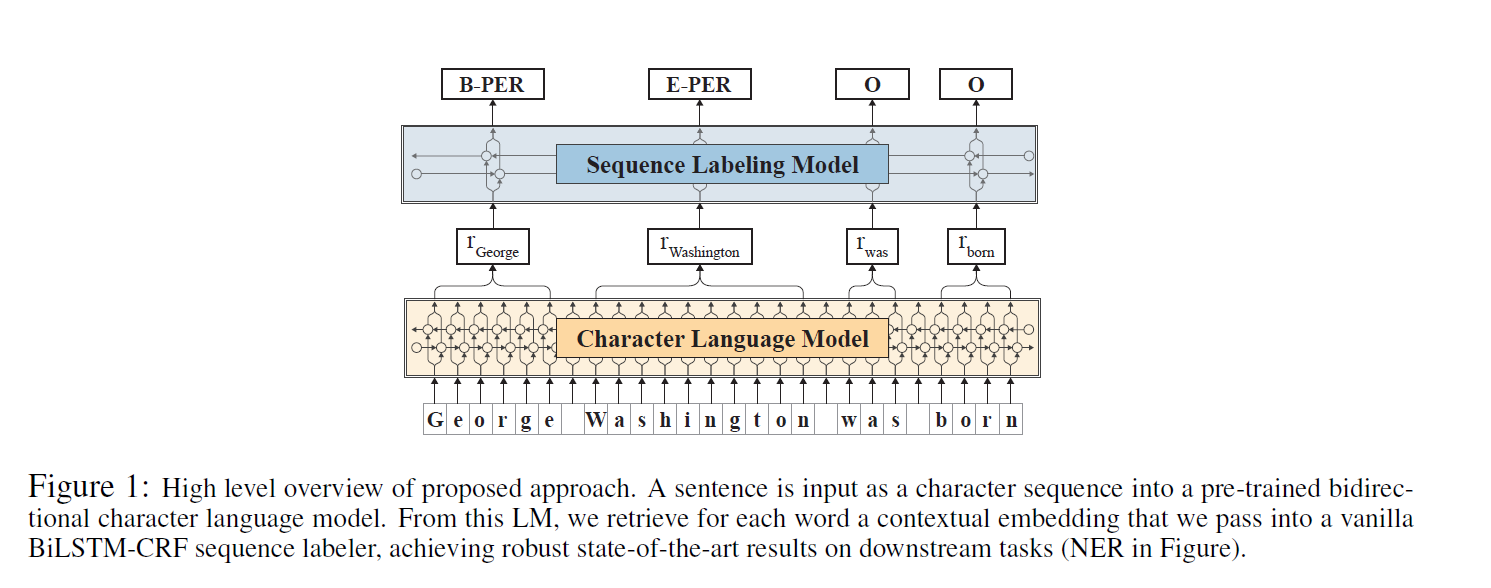
对没一句话作为一个字符序列传递给双向字符级的语言模型,从语言模型中提取每一个词的embedding,这个embedding可以用于BiLSTM-CRF序列标注模型的中。
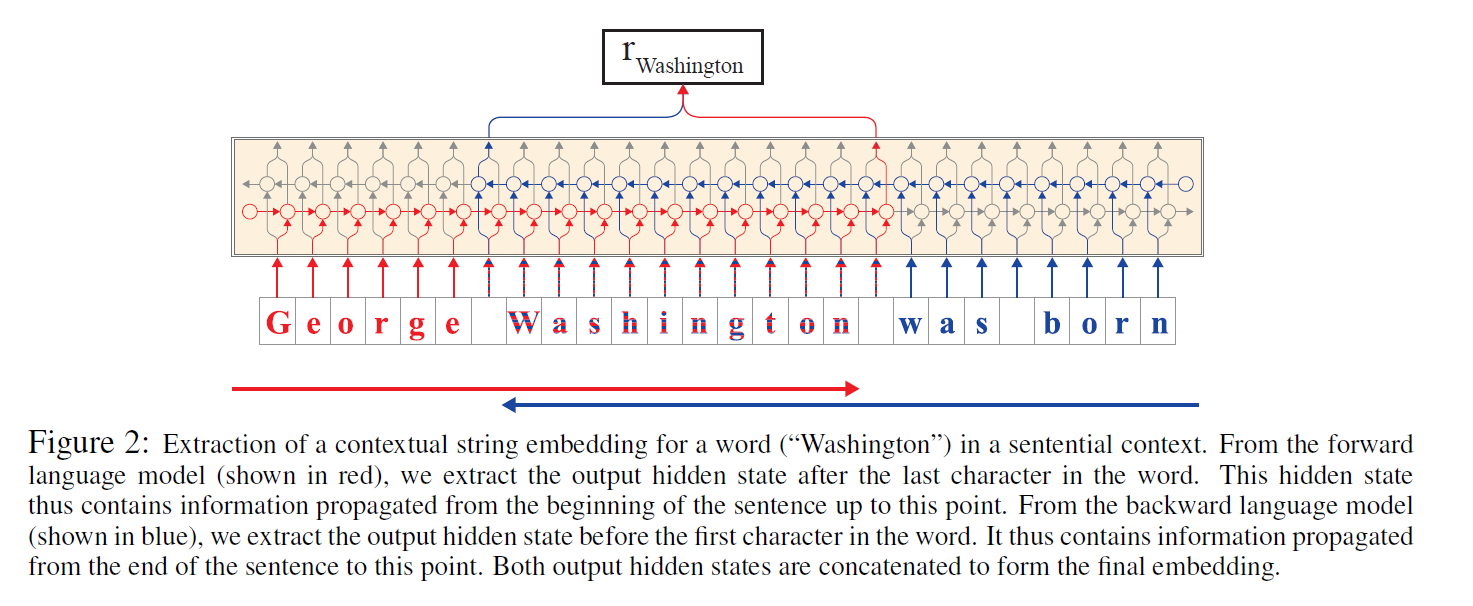
实验
论文做了几个尝试(different stackings of embeddings)。
PROPOSED : 只使用预训练的contextual string embeddings。就是上图所示
PROPOSED+WORD:加入预训练的word embedding
$$$$
$$
w_i=\begin{bmatrix} w^{ChatLM}_i\\w^{Glove}_i \ \end{bmatrix}
$$PROPOSED+CHAR :加入char embedding
PROPOSED+WORD+CHAR
PROPOSED+ALL : Finally, we evaluate a setup that uses all four embeddings. Since Peters et al. (2018)
embeddings are only distributed for English, we use this setup only on the English tasks.
实验结果
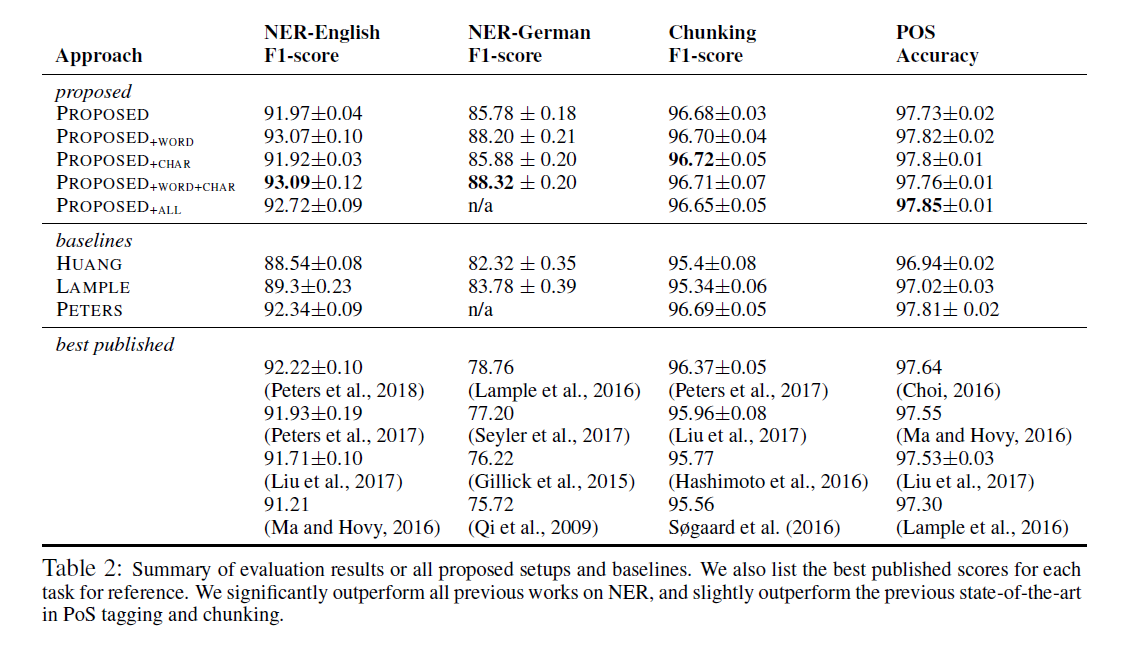
总结
字符级语言模型独立于token和固定的词典。
可以产生更强的字符特征,用于下游的NLP任务,比如NER。
- 这个模型有一个更小的字典(distinct characters vs. distinct words),在一个GPU上只需要训练一周,而基于词的语言模型需要在32个GPU上训练五个星期。(Peters et al. (2017))
参考
- Contextual String Embeddings for Sequence Labeling – Alan Akbik, Duncan Blythe and Roland Vollgraf.