介绍
预训练的词向量是很多神经语言理解模型的关键部分,然而学习高质量的表示是很有挑战性的。一个好的词向量应该包含:(1)能够建模词的复杂字符特征(比如语法和语义),(2)能够在不同语境有不同反映(如多义词)。这篇论文中,引入一种新类型的深度上下文词表示,可以应对这些挑战,并且可以容易与当前存在的模型进行整合,有效提升了一系列有挑战的语言理解问题的最优性能。
模型
ELMO是一个语言模型中中间层表示的特点任务的组合。对于每一个token$t_k$,一个L层的双向语言模型计算$2L+1$表征。
$$
R_k={ x^{LM}_k,h^{LM}_{k,j}|j=1,\dots ,L} \ ={h^{LM}_{k,j}|j=1,\dots ,L}
$$
$h^{LM}_{k,0}$是token层,$h^{LM}_{k,j}$是双向LSTM层
$$
ELMo^{task}_k=E(R_k;\theta^task)=\gamma^{task}\sum^L_{j=0}s^{task}_jh^{LM}_{k.j}
$$
最简单的情况下,ELMO只选择顶层,即$E(R_k)=h^{LM}_{k,L}$,如TagLM(Peters et al., 2017 )和 CoVe(McCann et al., 2017) 。$s^{task}$是softmax归一化权重。ELMo的训练过程与一般语言模型相似,在使用时需要对各层输出进行加权。
将ELMo模型加入到有监督的NLP任务中
三种方法
- 先固定biLM中权重,然后拼接$ELMo^{task}_k$和$x_k$为$[x_k;ELMo^{task}_k]$,再将这个向量丢到任务RNN中
- 在task RNN输出的时候使用$[h_k;ELMo^{LM}_k]$替换$h_k$。
- 在ELMo中加入dropout以及给loss增加$\lambda||w||^2_2$
实验
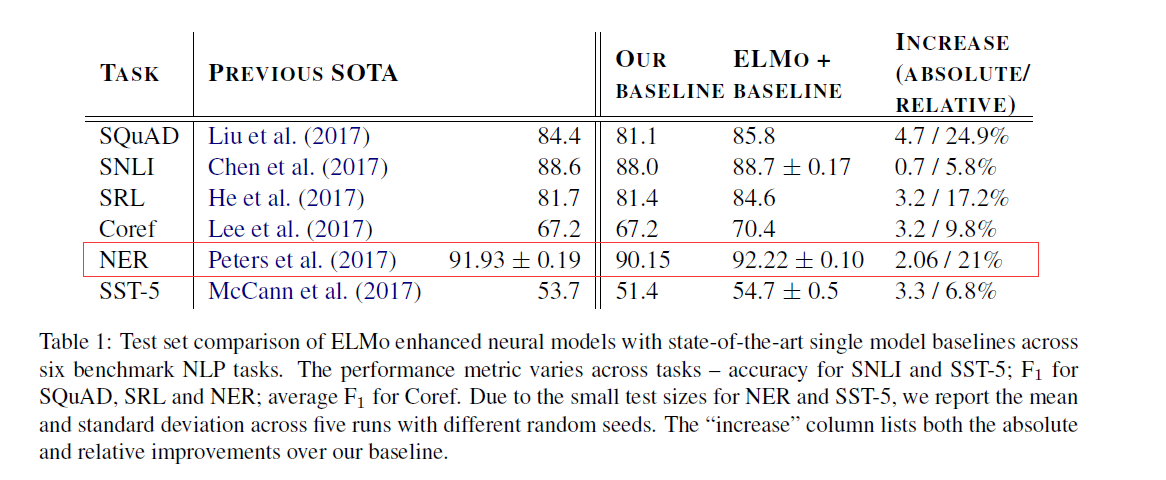
在NER任务上,ELMo加强的BiLSTM-CRF的f1值为92.22%。
总结
- 感觉和17年ACL的TagLM很像,只是在LM上加了一些改动,对不同的层的加入一些权重。主要的问题还是在训练语言模型上。
- 词向量应该随着上下文的改变而改变
- 不同层的双向RNN可以编码不同类型的信息。ELMo第一层输出包含更多的句法信息,而第二层输出包含更多的语义信息。
参考
Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802.05365, 2018.