介绍
对于NLP任务,从无标签文本中学习预训练的embedding已经是神经网络的一个标准部分。在这篇论文中,提出了将一个双向的语言模型的context embedding引入序列标注任务中,在NER和chunking两个标准数据集上进行了实验,证明了与其他的某些使用迁移学习和使用附加标注数据和特定任务字典的联合学习相比,效果都要好,超过了以往所有的模型。
贡献
模型
语言模型
一个语言模型是计算一个序列$(t_1,t_2,…,t_N)$的概率
$$
p(t_1,t_2,\dots,t_N)=\prod_{k=1}^Np(t_k|t_1,t_2,\dots,t_k-1)
$$
TagLM(language-model-augmented sequence tagger)
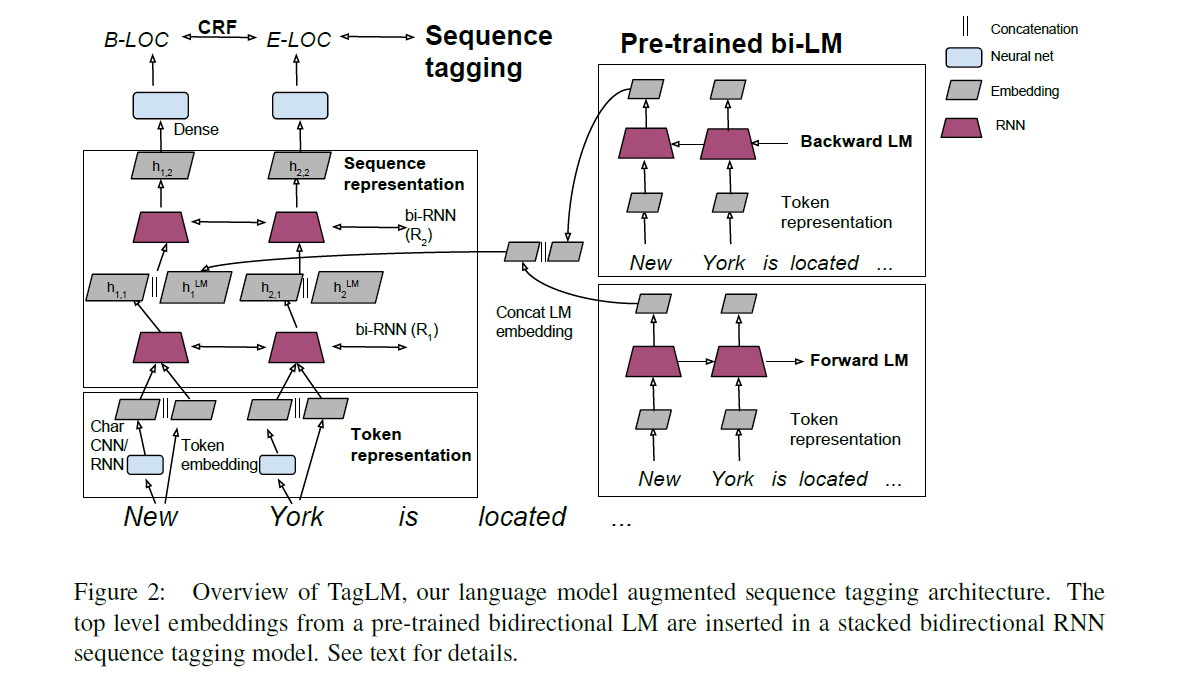
图的左边是标准的LSTM-CRF模型,这里LSTM使用了两层。图的右边是语言模型。语言模型的加入是在第一层双向LSTM输出之后进行拼接的,因为这个位置效果最好。作者做了三个尝试,将LM embeddings分别拼接在第一层RNN的输入、第一层RNN的输出、第二层RNN的输出。实验中,第二种方案的表现最好。 正是上图展示的那样。
未实验的其他LM embedding加入方式
- 在第一层RNN拼接之后加入一个非线性映射$ f([ h_{k,1};h^{LM}_k])$
- 对 LM embedding加入attention机制
实验
在CoNLL2003 NER任务和CoNLL Chunking 任务上进行了实验。
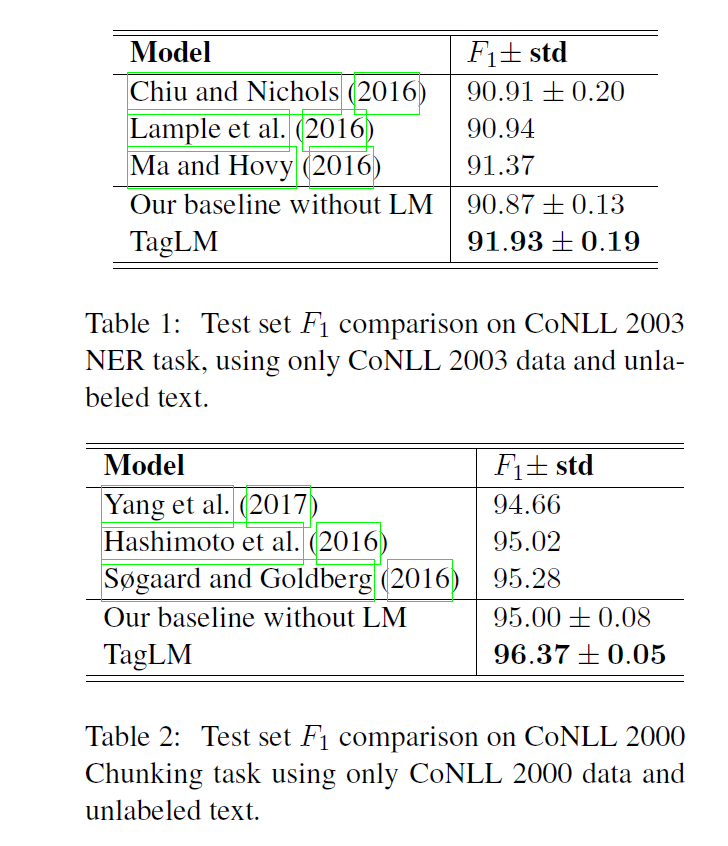
分析
###1.How to use LM embedding?
作者在不同的位置上对LM embedding进行拼接
在第一层RNN的输入时,
$$$$
$$
x_k=[c_k;,w_k;h^{LM}_k]
$$在第一层RNN输出时
$$
h_{k,1}=[h_{k,1};h^{LM}_k]
$$在第二层RNN输出时
$$
h_{k,2}=[h_{k,2};h^{LM}_k]
$$
实验结果
结果表明,在第一层RNN输出时拼接效果做好
2.Does it matter which language model to use?
不同语言模型的影响。
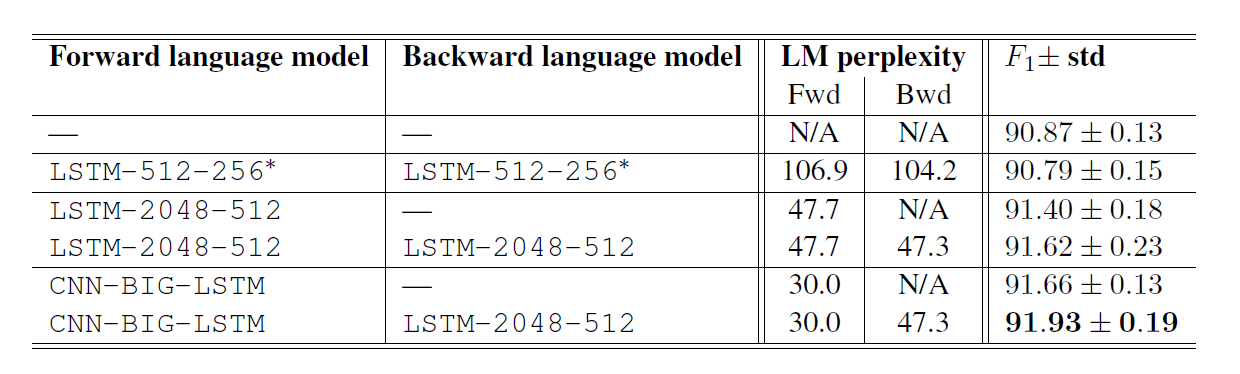
语言模型的大小是重要的。
双向语言模型比前向语言模型要好
###3.Importance of task specific RNN
不使用RNN只使用全连接层,$F_1$为88.71,低于baseline。
4.Dataset size
作者的方法对训练集大小的依赖很小,在使用更大的训练集时,语言模型会有一个明显的提升。
5.Number of parameters
没大看懂对比
6.Does the LM transfer across domains?
这篇论文证明语言模型是可以跨领域的。将新闻领域训练出来的语言模型,用到科学论文的任务上,也有效果也有提升。
总结
- LM embedding 与word embedding类似语义信息,LM embedding感觉更像序列级别的,在加入LM embedding 到RNN中时,在与第一层RNN拼接时效果也是最好的。word embedding也是包含上下文信息的,感觉两个embedding包含的信息有部分的重叠,虽然有一个点的提升。
- 对人们比较关心的几个问题都做了附加的分析,让人心服口服,值得学习。
- 即使只是对基础模型的一个细小改动,增加一个类型信息(本文是语言模型的上下文信息),如果把实验做的充分,结果显著,也是可以发出来文章的。
- 感觉得presentation者得天下……
参考
[1] Rei, M. (2017). Semi-supervised Multitask Learning for Sequence Labeling. ACL. http://doi.org/10.18653/v1/P17-1194